
Memvid replaces vector databases with a single MP4 file. It packages millions of text chunks, embeddings, search structures, and metadata into one portable artifact, and offers semantic search directly from the file — no server, no vector DB, and no complex infra.
What is Memvid?
Memvid is a portable AI memory system that stores data, indexes, and embeddings inside an MP4 container. The idea is simple: instead of running a dedicated vector database, put everything into a single file that agents can carry, share, and query locally. That makes memory model-agnostic and infrastructure-free.
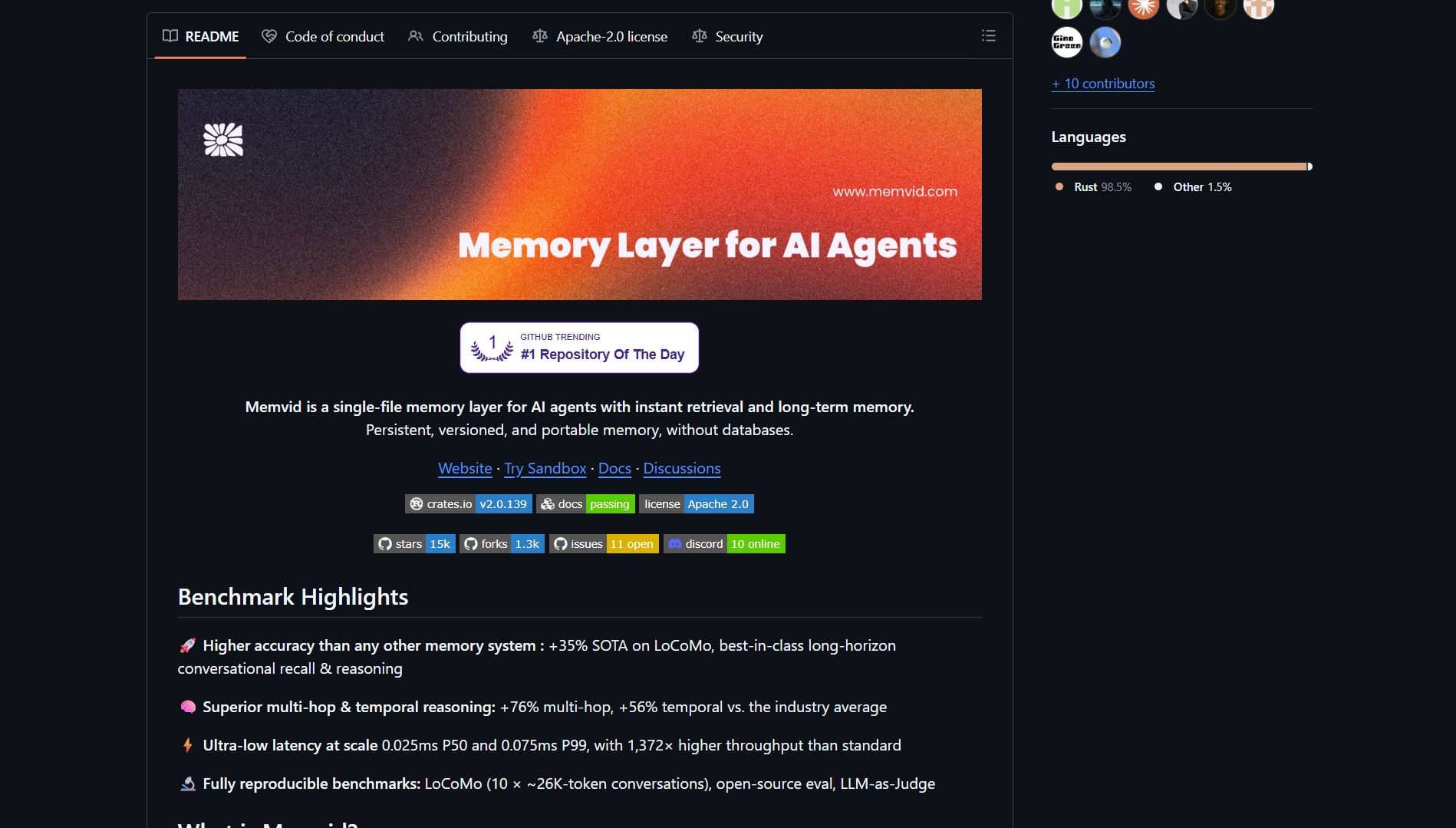
Encoding arbitrary text into a media container is an engineering tradeoff. MP4 gives you linearity, timestamps, and wide OS support, but verify performance and codec interactions for your dataset and search patterns.
How it works
At a high level, Memvid serializes text chunks, embeddings, and index structures into frames or metadata tracks inside an MP4. A lightweight reader extracts only the frames needed for a semantic query, reconstructs context, and returns results quickly — avoiding a separate DB server.
# quick start
git clone https://github.com/memvid/memvid
cd memvid
# read the README for build and indexing instructions
# example: index a folder of notes and run a local search
| Component | Purpose |
|---|---|
| Container (MP4) | Stores chunks, embeddings, and metadata in a single file |
| Indexer | Converts documents into embeddings and writes them into tracks/frames |
| Reader | Executes semantic search by seeking to relevant timestamps and decoding needed frames |
| Tooling | Import/export, compression, and utilities for portability |
Start with a small dataset and measure search latency and file size. Test across OSes and players — some tools may touch or reindex MP4 metadata unexpectedly.
Community reactions
“I’ve read the git a few times but am still super confused why encoding the same data into mp4 files is better? Any encoding strategy is fine for arbitrary text data, what’s mp4 offering? Linearity and timestamps?” — @absition
Project link:
https://github.com/memvid/memvid
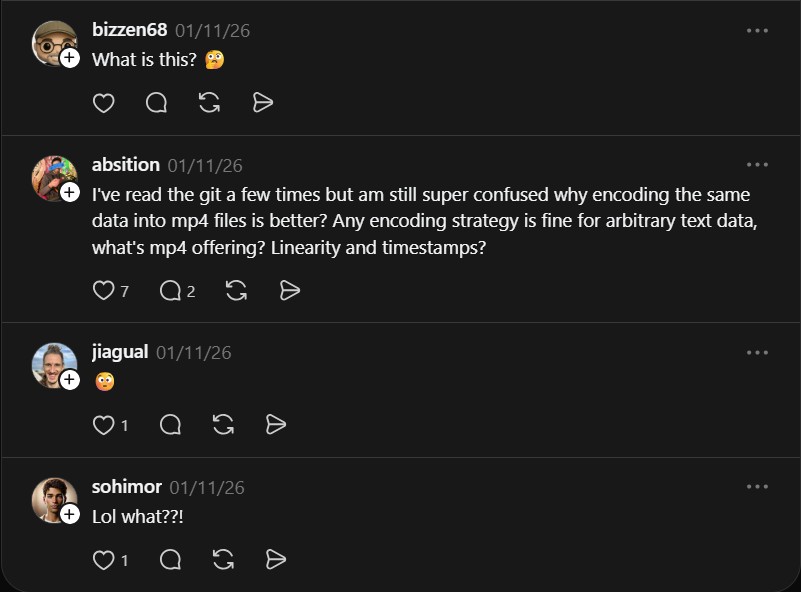
Claims about replacing vector DBs deserve scrutiny. Consider tradeoffs: random-access vs linear seeks, codec side effects, backup workflows, and compatibility with your agent runtime. Also verify licensing for any codec/tooling used in production.
Final thoughts
Memvid is an intriguing distribution idea: memory as a single portable artifact rather than a running service. For prototypes and research it can simplify deployment and sharing; for production, validate latency, durability, and how the format integrates with your retrieval pipelines.