Cara Simpel Membuat AI Agent WhatsApp dengan Hermes
Membuat AI agent di WhatsApp kini semakin mudah berkat framework seperti Hermes. Developer cukup menghubungkan WhatsApp dengan API ChatGPT untuk membuat chatbot otomatis yang bisa menjawab pesan secara real-time.
Kirim pesan ke nomor bot WhatsApp. AI agent kini sudah bisa membalas otomatis menggunakan ChatGPT.
Closing
Dengan Hermes dan API ChatGPT, developer dapat membuat AI agent WhatsApp hanya dalam beberapa menit tanpa membangun sistem dari nol. Pendekatan ini cocok untuk eksperimen, customer support, maupun automasi bisnis sederhana.
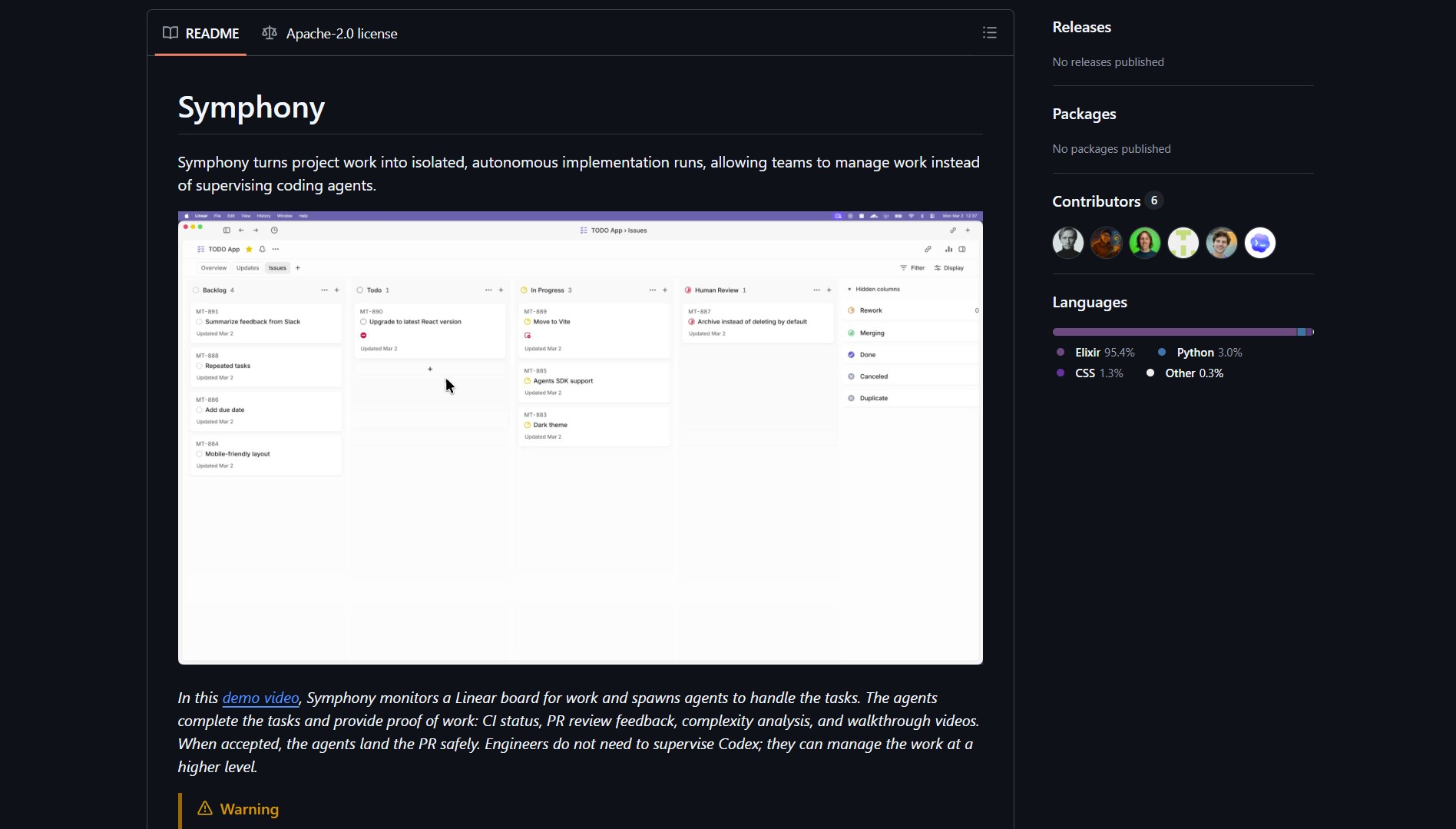
Symphony is an orchestration layer from OpenAI that automates the ticket-to-PR lifecycle. It watches issue trackers like Linear, spawns isolated workspaces for new tickets, and assigns autonomous agents to implement features end to end. The goal is to remove the human middleman from routine engineering workflows.
symphony repo
Symphony hooks into Linear and other trackers to detect new tickets in real time. It creates ephemeral environments so each task runs in isolation. The agent writes code, runs tests, opens PRs, responds to review feedback, and generates a walkthrough video. This is similar to how you can use Cline as an AI coding assistant for targeted code generation, but Symphony owns the full lifecycle from ticket to merge.
Symphony combines four core components. The monitor watches for new tickets. The workspace manager spins up isolated environments. The autonomous agent implements features, runs test suites, and files PRs. The CI integrator gates merges until all checks pass. You can pair Symphony with a self-hosted offline AI platform for teams that need stricter data control over their agent infrastructure.
Threads user, in response to How to Automate the Ticket-to-PR Cycle with Symphony
Start with a restricted pilot on small repos and noncritical branches. Set explicit rollback policies before scaling. Measure flakiness, test coverage, and PR quality to decide whether the agent pipeline is ready for production use. You can also look at Career-Ops for another example of agent-driven workflow automation applied to job searching.
The Catch
Symphony changes the human role from implementer to reviewer and manager of agent behavior. Autonomous development agents carry safety, security, and compliance risks. Run experiments in isolated labs and require human approval for production merges. Keep strong observability, audit logs, and a clear rollback strategy. The practical limit is trust in agent output, so validate everything before landing.
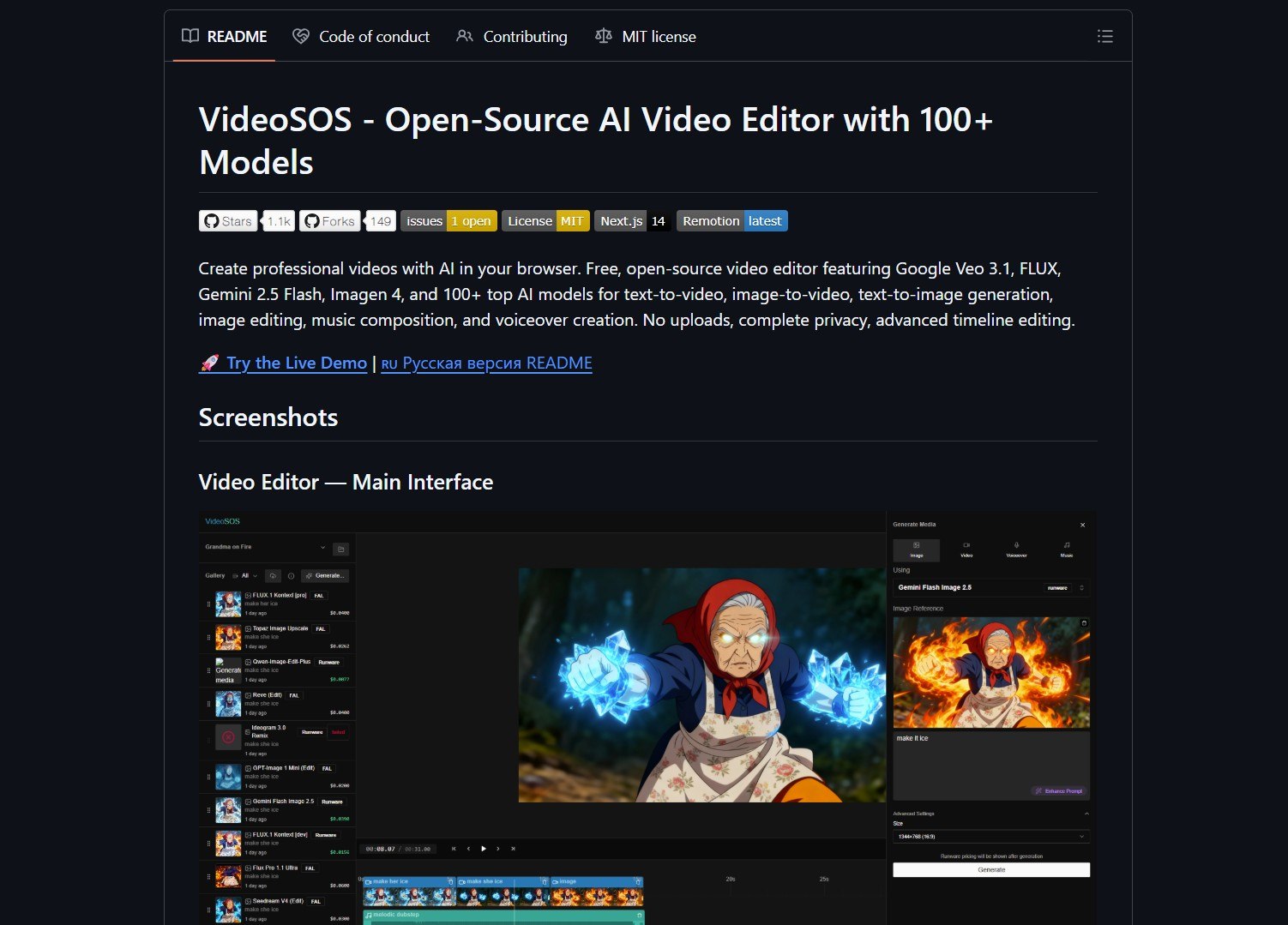
VideoSOS is an open-source, browser-first video editor that brings over 100 AI models into your browser. It handles text-to-video, image-to-video, image editing, music composition, and voiceover creation without uploading media to the cloud. The repo bundles integrations with fal.ai and Runware.ai and supports models like Google Veo 3.1, Gemini 2.5 Flash, and Imagen 4.
videosos repo
The stated goal is zero uploads and complete privacy by running as much as possible in the client or via local runtimes. You can generate short clips from prompts, edit frames, create voiceovers, and assemble multi-track projects on a standard timeline. This makes it a strong option for privacy-conscious content creation and rapid video prototyping.
Key Features
VideoSOS offers broad model coverage for video, image, and audio tasks. Its timeline editor supports standard NLE workflows for assembling and polishing multi-track projects. The local-first promise means no uploads, subject to which models actually run on your hardware.
It supports text-to-video and image-to-video generation, image editing, text-to-speech with multiple synthesis engines, and music composition. You can also build and scale AI agents for broader automation workflows using a self-hosted offline AI platform alongside your media tools.
VideoSOS wires together model runtimes, a web UI timeline editor, and integration adapters to switch providers. Where local runtimes are not possible, the project provides provider adapters for fal.ai and Runware.ai so generation can still happen without user-managed servers. This is similar to how you can route 1600 AI models with a unified gateway for flexible provider switching.
Threads user, in response to How to Use VideoSOS for Browser Video Editing with 100+ AI Models
Start with a single generation pipeline on a local machine with known GPU or CPU capability before attempting a full 100-model experiment. The quick start is straightforward: clone the repo, install local runtimes or configure provider adapters, and test a text-to-image-to-video pipeline.
The Catch
Claims about running proprietary models locally should be validated. Many named models like Gemini and Imagen are not fully open-source or available for local execution without licensing. Large model claims are resource intensive and sometimes conflate remote provider integrations with true local execution. Verify which models the repo runs locally and respect licensing for proprietary models. Evaluate GPU or VRAM requirements and disk capacity before experimenting.
VideoSOS is compelling as a distribution idea: a browser editor that unifies many media models under a single timeline workflow. The practical limits are hardware and model licensing, so validate runtimes and start with a constrained pilot.
VideoSOS is an open-source, browser-first video editor that brings over 100 AI models into your browser. It handles text-to-video, image-to-video, image editing, music composition, and voiceover creation without uploading media to the cloud. The repo bundles integrations with fal.ai and Runware.ai and supports models like Google Veo 3.1, Gemini 2.5 Flash, and Imagen 4.
videosos repo
The stated goal is zero uploads and complete privacy by running as much as possible in the client or via local runtimes. You can generate short clips from prompts, edit frames, create voiceovers, and assemble multi-track projects on a standard timeline. This makes it a strong option for privacy-conscious content creation and rapid video prototyping.
Key Features
VideoSOS offers broad model coverage for video, image, and audio tasks. Its timeline editor supports standard NLE workflows for assembling and polishing multi-track projects. The local-first promise means no uploads, subject to which models actually run on your hardware.
It supports text-to-video and image-to-video generation, image editing, text-to-speech with multiple synthesis engines, and music composition. You can also build and scale AI agents for broader automation workflows using a self-hosted offline AI platform alongside your media tools.
VideoSOS wires together model runtimes, a web UI timeline editor, and integration adapters to switch providers. Where local runtimes are not possible, the project provides provider adapters for fal.ai and Runware.ai so generation can still happen without user-managed servers. This is similar to how you can route 1600 AI models with a unified gateway for flexible provider switching.
Threads user, in response to How to Use VideoSOS for Browser Video Editing with 100+ AI Models
Start with a single generation pipeline on a local machine with known GPU or CPU capability before attempting a full 100-model experiment. The quick start is straightforward: clone the repo, install local runtimes or configure provider adapters, and test a text-to-image-to-video pipeline.
The Catch
Claims about running proprietary models locally should be validated. Many named models like Gemini and Imagen are not fully open-source or available for local execution without licensing. Large model claims are resource intensive and sometimes conflate remote provider integrations with true local execution. Verify which models the repo runs locally and respect licensing for proprietary models. Evaluate GPU or VRAM requirements and disk capacity before experimenting.
VideoSOS is compelling as a distribution idea: a browser editor that unifies many media models under a single timeline workflow. The practical limits are hardware and model licensing, so validate runtimes and start with a constrained pilot.
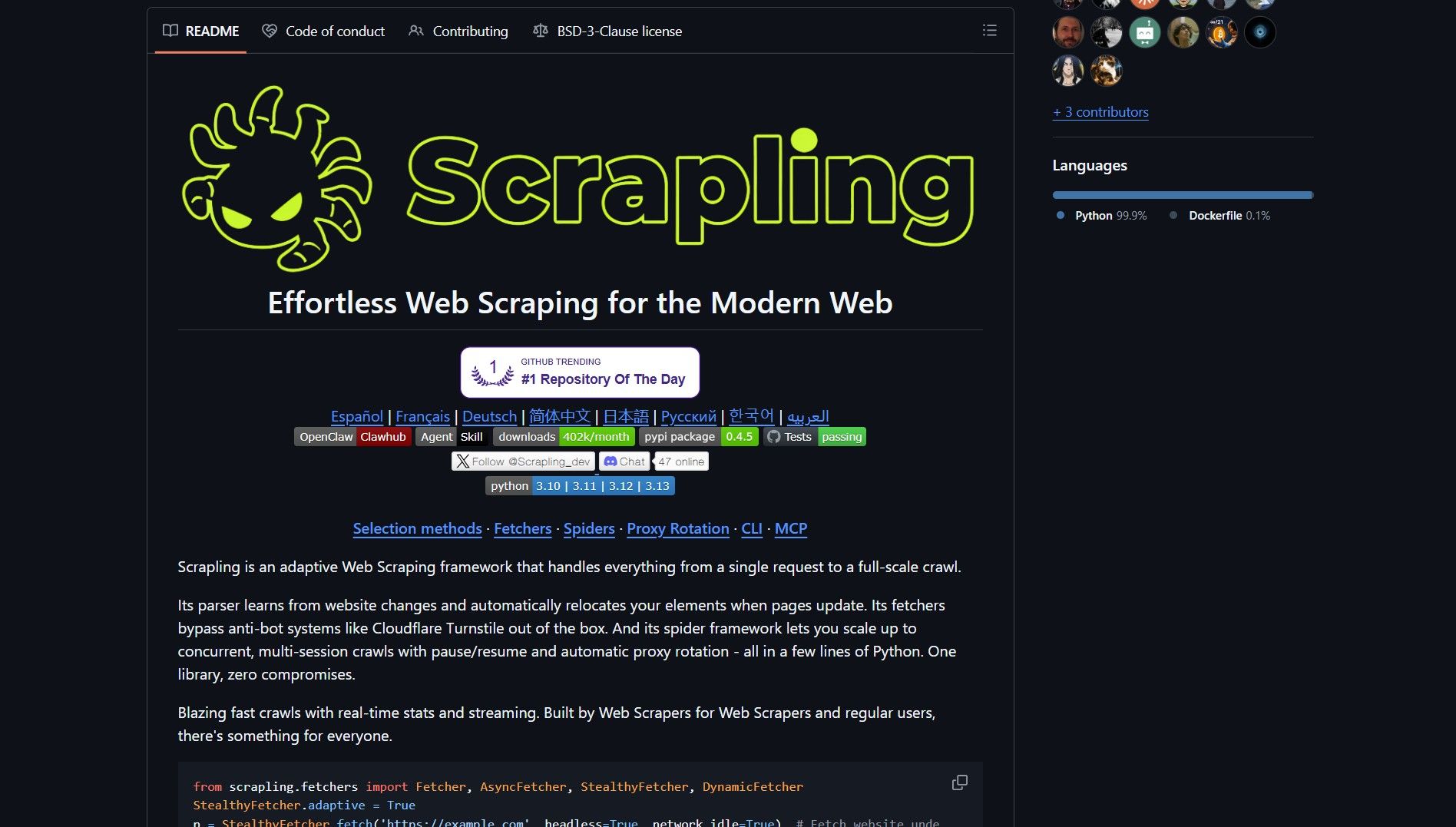
Scrapling is an open-source web scraping framework by D4Vinci that bypasses Cloudflare protections natively. The adaptive parser relocates selectors when pages change, reducing maintenance. It supports proxy rotation, pause and resume, and concurrent multi-session crawls.
scrapling repo
The fetchers include anti-bot techniques that remove the need for separate scraping stacks. The parser runs up to 774x faster than BeautifulSoup for some workloads. Developers can integrate Scrapling into agentic pipelines, similar to how Gobii runs durable autonomous agents in production environments.
How It Works
Scrapling uses an adaptive parser that learns from layout changes. When a target site updates its HTML structure, the parser relocates elements automatically. The anti-bot fetchers handle Cloudflare Turnstile and other protections without manual configuration.
Threads user, in response to How to Bypass Cloudflare with Scrapling
For large-scale crawls, the spider framework manages concurrent sessions with automatic proxy rotation. It supports pause and resume, so interrupted crawls do not restart from scratch. To get started, run git clone https://github.com/D4Vinci/Scrapling and follow the repo instructions to configure fetchers and parser.
Use Cases
SaaS agents use Scrapling to pull site data without rebuilding frontends after layout changes. Data engineering pipelines run large-scale crawls with pause and resume for reliability. Developers building full-stack AI solutions with LangChain and LangGraph can add Scrapling as a data ingestion layer.
Claims about bypassing protections are sensitive. Evaluate legal and ethical considerations before deploying at scale. Validate the parser on your target sites and measure throughput first. Start with a small pilot on low-traffic targets before scaling with proxy settings.
Scrapling is an open-source web scraping framework by D4Vinci that bypasses Cloudflare protections natively. The adaptive parser relocates selectors when pages change, reducing maintenance. It supports proxy rotation, pause and resume, and concurrent multi-session crawls.
scrapling repo
The fetchers include anti-bot techniques that remove the need for separate scraping stacks. The parser runs up to 774x faster than BeautifulSoup for some workloads. Developers can integrate Scrapling into agentic pipelines, similar to how Gobii runs durable autonomous agents in production environments.
How It Works
Scrapling uses an adaptive parser that learns from layout changes. When a target site updates its HTML structure, the parser relocates elements automatically. The anti-bot fetchers handle Cloudflare Turnstile and other protections without manual configuration.
Threads user, in response to How to Bypass Cloudflare with Scrapling
For large-scale crawls, the spider framework manages concurrent sessions with automatic proxy rotation. It supports pause and resume, so interrupted crawls do not restart from scratch. To get started, run git clone https://github.com/D4Vinci/Scrapling and follow the repo instructions to configure fetchers and parser.
Use Cases
SaaS agents use Scrapling to pull site data without rebuilding frontends after layout changes. Data engineering pipelines run large-scale crawls with pause and resume for reliability. Developers building full-stack AI solutions with LangChain and LangGraph can add Scrapling as a data ingestion layer.
Claims about bypassing protections are sensitive. Evaluate legal and ethical considerations before deploying at scale. Validate the parser on your target sites and measure throughput first. Start with a small pilot on low-traffic targets before scaling with proxy settings.
Scrapling is an open-source web scraping framework by D4Vinci that bypasses Cloudflare protections natively. The adaptive parser relocates selectors when pages change, reducing maintenance. It supports proxy rotation, pause and resume, and concurrent multi-session crawls.
scrapling repo
The fetchers include anti-bot techniques that remove the need for separate scraping stacks. The parser runs up to 774x faster than BeautifulSoup for some workloads. Developers can integrate Scrapling into agentic pipelines, similar to how Gobii runs durable autonomous agents in production environments.
How It Works
Scrapling uses an adaptive parser that learns from layout changes. When a target site updates its HTML structure, the parser relocates elements automatically. The anti-bot fetchers handle Cloudflare Turnstile and other protections without manual configuration.
Threads user, in response to How to Bypass Cloudflare with Scrapling
For large-scale crawls, the spider framework manages concurrent sessions with automatic proxy rotation. It supports pause and resume, so interrupted crawls do not restart from scratch. To get started, run git clone https://github.com/D4Vinci/Scrapling and follow the repo instructions to configure fetchers and parser.
Use Cases
SaaS agents use Scrapling to pull site data without rebuilding frontends after layout changes. Data engineering pipelines run large-scale crawls with pause and resume for reliability. Developers building full-stack AI solutions with LangChain and LangGraph can add Scrapling as a data ingestion layer.
Claims about bypassing protections are sensitive. Evaluate legal and ethical considerations before deploying at scale. Validate the parser on your target sites and measure throughput first. Start with a small pilot on low-traffic targets before scaling with proxy settings.
Scrapling is an open-source web scraping framework by D4Vinci that bypasses Cloudflare protections natively. The adaptive parser relocates selectors when pages change, reducing maintenance. It supports proxy rotation, pause and resume, and concurrent multi-session crawls.
scrapling repo
The fetchers include anti-bot techniques that remove the need for separate scraping stacks. The parser runs up to 774x faster than BeautifulSoup for some workloads. Developers can integrate Scrapling into agentic pipelines, similar to how Gobii runs durable autonomous agents in production environments.
How It Works
Scrapling uses an adaptive parser that learns from layout changes. When a target site updates its HTML structure, the parser relocates elements automatically. The anti-bot fetchers handle Cloudflare Turnstile and other protections without manual configuration.
Threads user, in response to How to Bypass Cloudflare with Scrapling
For large-scale crawls, the spider framework manages concurrent sessions with automatic proxy rotation. It supports pause and resume, so interrupted crawls do not restart from scratch. To get started, run git clone https://github.com/D4Vinci/Scrapling and follow the repo instructions to configure fetchers and parser.
Use Cases
SaaS agents use Scrapling to pull site data without rebuilding frontends after layout changes. Data engineering pipelines run large-scale crawls with pause and resume for reliability. Developers building full-stack AI solutions with LangChain and LangGraph can add Scrapling as a data ingestion layer.
Claims about bypassing protections are sensitive. Evaluate legal and ethical considerations before deploying at scale. Validate the parser on your target sites and measure throughput first. Start with a small pilot on low-traffic targets before scaling with proxy settings.
Symphony is an orchestration layer for autonomous engineering runs. It hooks into Linear, spawns isolated workspaces, and assigns an AI agent to implement a ticket end to end. The agent writes code, runs tests, opens PRs, responds to reviews, and lands the change when CI passes.
symphony repo
What Symphony does
Symphony automates the full ticket-to-PR lifecycle. It monitors issue trackers for new tickets and creates ephemeral workspaces for each one. An autonomous agent gets the task context and test harness, then implements features, runs tests, and files pull requests.
The agent also handles review feedback and updates the PR until CI passes. Symphony can generate a walkthrough video before landing the change. This shifts the developer role from implementer to reviewer.
Symphony combines event triggers, ephemeral environments, and autonomous agents. The monitor watches Linear for new tickets. When a ticket appears, the workspace manager creates an isolated environment. The agent receives the task context and test harness.
Threads user, in response to How to Automate the Ticket-to-PR Cycle with Symphony
The agent then implements the feature, runs tests, and opens a pull request. It responds to review feedback and updates the PR until tests pass. When CI succeeds, the change lands automatically.
The catch
Autonomous development agents carry safety and security risks. Symphony should run in isolated labs with human approvals for production merges. Start with small repos, noncritical branches, and explicit rollback policies. Measure flakiness, test coverage, and PR quality before scaling.
Symphony is an orchestration layer for autonomous engineering runs. It hooks into Linear, spawns isolated workspaces, and assigns an AI agent to implement a ticket end to end. The agent writes code, runs tests, opens PRs, responds to reviews, and lands the change when CI passes.
symphony repo
What Symphony does
Symphony automates the full ticket-to-PR lifecycle. It monitors issue trackers for new tickets and creates ephemeral workspaces for each one. An autonomous agent gets the task context and test harness, then implements features, runs tests, and files pull requests.
The agent also handles review feedback and updates the PR until CI passes. Symphony can generate a walkthrough video before landing the change. This shifts the developer role from implementer to reviewer.
Symphony combines event triggers, ephemeral environments, and autonomous agents. The monitor watches Linear for new tickets. When a ticket appears, the workspace manager creates an isolated environment. The agent receives the task context and test harness.
Threads user, in response to How to Automate the Ticket-to-PR Cycle with Symphony
The agent then implements the feature, runs tests, and opens a pull request. It responds to review feedback and updates the PR until tests pass. When CI succeeds, the change lands automatically.
The catch
Autonomous development agents carry safety and security risks. Symphony should run in isolated labs with human approvals for production merges. Start with small repos, noncritical branches, and explicit rollback policies. Measure flakiness, test coverage, and PR quality before scaling.